本文最后更新于224 天前,其中的信息可能已经过时,如有错误请发送邮件到2773434682@qq.com
第一个python大项目就是课设,不过里面的代码是我之前跑过的,拼拼凑凑就成了课程设计,哈哈哈
这是我的代码
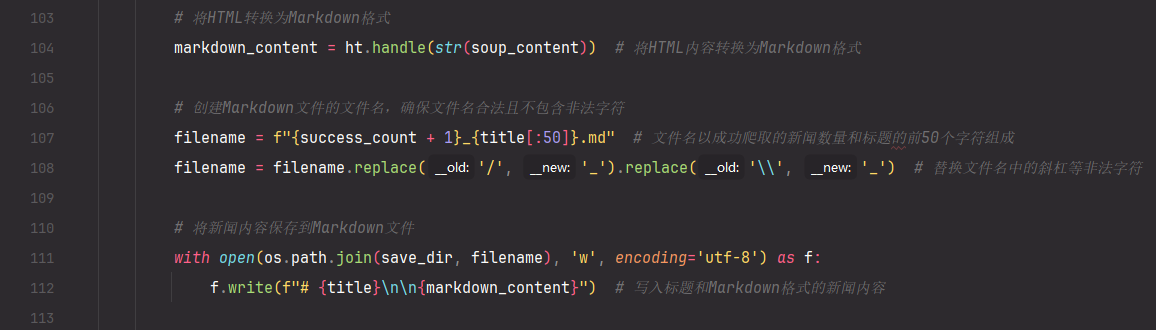
获取到html之后,将内容转化为 .md 格式的文件以便更简介的显示内容格式、排版
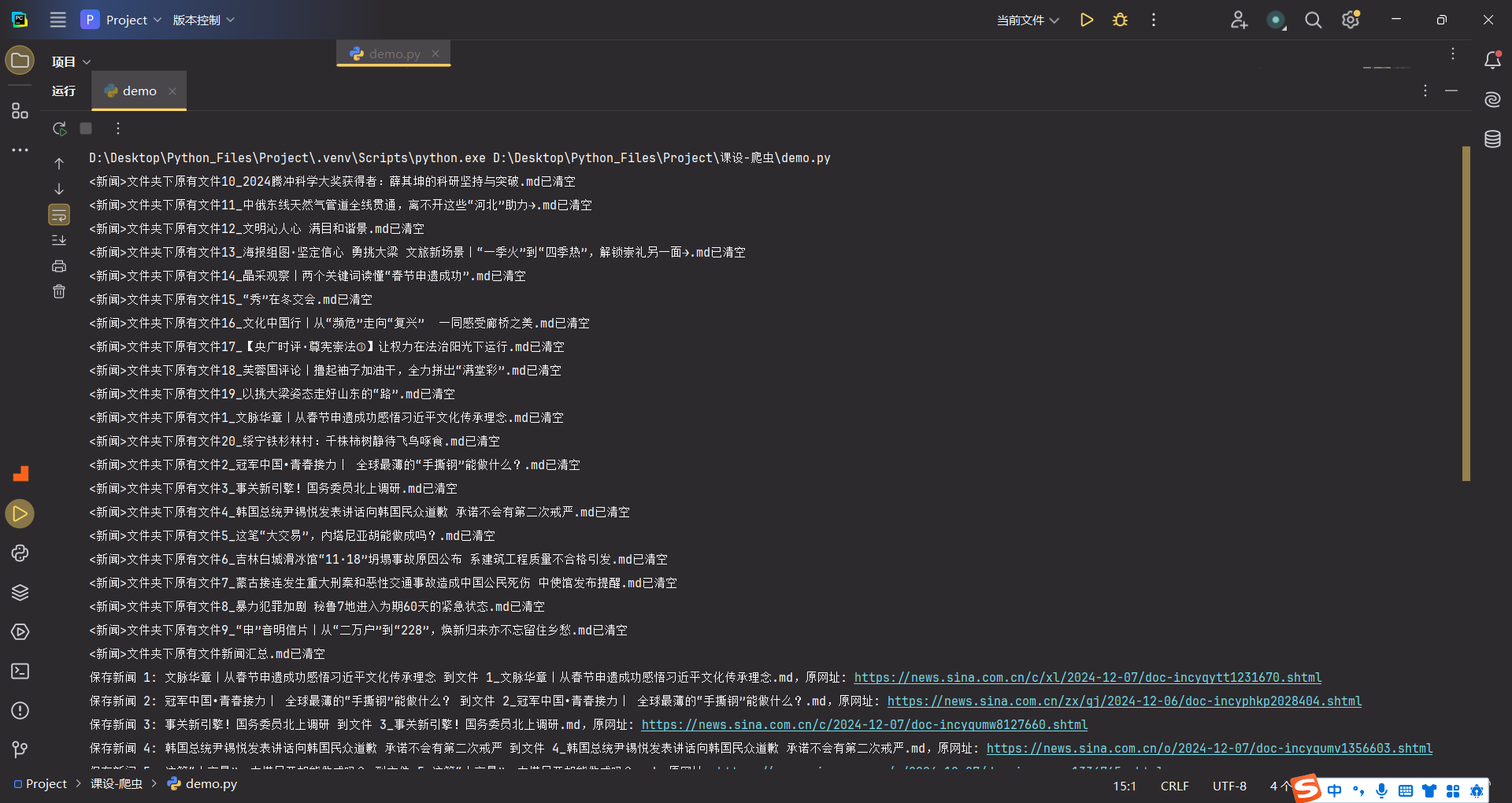
并且有检错功能,如果某个新闻获取失败,可以重新获取下一个,并且能保证成功获取的数量不变


代码运行时的提示,如果保存的文件夹下已有旧新闻文件,就先清除该文件再重新生成
下面是我的代码及AI注释
# 导入需要的库
import os # 用于操作系统相关功能,如文件和文件夹的操作
from urllib.parse import urljoin # 用于拼接URL,确保图片或视频链接的完整性
import html2text # 用于将HTML内容转换为Markdown格式
import requests # 用于发送HTTP请求,获取网页内容
from bs4 import BeautifulSoup # 用于解析HTML内容
# 1. 定义要爬取的新浪新闻首页URL
url = "https://news.sina.com.cn/"
# 2. 发送HTTP请求获取网页内容
response = requests.get(url) # 向URL发送GET请求,获取响应
response.encoding = 'utf-8' # 设置网页的编码格式为UTF-8,防止乱码
# 3. 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.text, 'html.parser') # 用BeautifulSoup解析网页HTML
# 4. 获取新闻页面的所有链接
news_links = [] # 用于存储新闻链接的列表
# 遍历网页中的所有<a>标签,寻找包含新闻链接的标签
for a_tag in soup.find_all('a', href=True): # 找到所有带有href属性的<a>标签
link = a_tag['href'] # 获取标签的href属性值(即链接)
# 检查链接是否为新闻页面的有效链接
if 'news.sina.com.cn' in link and 'doc' in link: # 判断链接是否包含特定标识符,确保它是新闻链接
if link.startswith('/'): # 如果链接是相对路径,则将它转换为完整的URL
link = 'https://news.sina.com.cn' + link # 拼接完整URL
news_links.append(link) # 将有效的新闻链接加入列表
# 5. 创建保存爬取新闻的文件夹
save_dir = os.path.join(os.getcwd(), "新闻") # 获取当前工作目录,创建一个名为"新闻"的文件夹
if not os.path.exists(save_dir): # 检查文件夹是否已经存在
os.makedirs(save_dir) # 如果文件夹不存在,创建它
print("<新闻>文件夹下无内容,不需要清空")
else:
# 如果文件夹已经存在,清空文件夹中的所有内容
for filename in os.listdir(save_dir): # 遍历文件夹中的每个文件
file_path = os.path.join(save_dir, filename) # 获取文件的完整路径
if os.path.isfile(file_path): # 如果是文件而不是文件夹
print(f"<新闻>文件夹下原有文件{filename}已清空") # 打印删除文件的信息
os.remove(file_path) # 删除该文件
# 6. 初始化html2text转换器,用于将HTML转换为Markdown
ht = html2text.HTML2Text() # 创建HTML2Text对象
ht.ignore_images = False # 不忽略图片,转换时会保留图片链接
# 7. 初始化一个列表,用于保存新闻汇总的标题
summary_lines = []
# 8. 爬取新闻并保存为Markdown文件
success_count = 0 # 初始化成功爬取的新闻数量
for i, news_url in enumerate(news_links[:100], start=1): # 尝试获取前100条新闻,确保至少有20条成功
if success_count >= 20: # 如果已经成功获取20条新闻,停止爬取
break
try:
# 获取新闻页面的HTML内容
news_response = requests.get(news_url) # 发送GET请求,获取新闻页面内容
news_response.encoding = 'utf-8' # 设置编码为UTF-8,防止中文乱码
# 使用BeautifulSoup解析新闻页面的HTML
news_soup = BeautifulSoup(news_response.text, 'html.parser')
# 尝试获取新闻的标题,优先获取<h1>或<h2>标签
title_tag = news_soup.find(['h1', 'h2'], class_=['main-title', 'article-title']) # 查找标题
if title_tag: # 如果找到了标题标签
title = title_tag.get_text(strip=True) # 获取标题文本并去掉多余的空格
else:
title = "无法获取标题" # 如果找不到标题,使用默认值
# 获取新闻内容
content_tag = news_soup.find('div', class_='article') # 查找新闻内容区域
content = str(content_tag) if content_tag else "" # 如果找到了内容,就转为字符串;否则为空字符串
# 处理新闻中的视频内容
video_tags = news_soup.find_all(['video', 'iframe']) # 查找所有video或iframe标签
video_links = [] # 用于存储视频链接
for video_tag in video_tags:
# 如果是video标签,获取其src属性(视频URL)
if video_tag.name == 'video':
video_url = video_tag.get('src')
if video_url:
video_links.append(f"[视频]({urljoin(news_url, video_url)})") # 拼接视频的完整URL并存入列表
# 如果是iframe标签,获取其src属性(通常也包含视频)
elif video_tag.name == 'iframe':
video_url = video_tag.get('src')
if video_url:
video_links.append(f"[视频]({urljoin(news_url, video_url)})")
# 如果有视频链接,添加到新闻内容中
if video_links:
content += "\n\n" + "\n".join(video_links)
# 替换图片的URL为完整路径
soup_content = BeautifulSoup(content, 'html.parser') # 重新解析内容
for img_tag in soup_content.find_all('img'): # 查找所有img标签
img_url = img_tag.get('src') # 获取图片的src属性
if img_url:
img_tag['src'] = urljoin(news_url, img_url) # 拼接完整的图片URL
# 将HTML转换为Markdown格式
markdown_content = ht.handle(str(soup_content)) # 将HTML内容转换为Markdown格式
# 创建Markdown文件的文件名,确保文件名合法且不包含非法字符
filename = f"{success_count + 1}_{title[:50]}.md" # 文件名以成功爬取的新闻数量和标题的前50个字符组成
filename = filename.replace('/', '_').replace('\\', '_') # 替换文件名中的斜杠等非法字符
# 将新闻内容保存到Markdown文件
with open(os.path.join(save_dir, filename), 'w', encoding='utf-8') as f:
f.write(f"# {title}\n\n{markdown_content}") # 写入标题和Markdown格式的新闻内容
# 将新闻标题和对应的文件名添加到汇总文件列表中,并加上序号
summary_lines.append(f"{success_count + 1}. [{title}]({filename})")
# 更新成功爬取的新闻数量
success_count += 1
# 输出新闻标题和对应的原网址
print(f"保存新闻 {success_count}: {title} 到文件 {filename},原网址: {news_url}")
except Exception as e:
# 如果遇到错误,输出错误信息并跳过当前新闻,继续爬取下一条
print(f"爬取新闻 {i} 失败: {e},跳过此新闻并继续爬取下一条新闻。")
continue # 获取失败时跳过当前新闻,继续处理下一条新闻
# 9. 将新闻汇总信息写入"新闻汇总.md"文件
summary_filename = os.path.join(save_dir, "新闻汇总.md") # 汇总文件的路径
with open(summary_filename, 'w', encoding='utf-8') as f:
f.write("# 新闻汇总\n\n") # 写入标题
f.write("\n".join(summary_lines)) # 写入所有新闻标题的链接列表
# 10. 输出保存成功的消息
print(f"新闻汇总文件已保存到 {summary_filename}")